

Les réseaux de neurone liquide : un pas vers l'IA frugale, éthique et responsable ?
Des réseaux de neurones, liquides ?
Un réseau de neurones classique (ou "solide") est un ensemble de nœuds interconnectés qui imitent le fonctionnement des neurones biologiques pour traiter des données. Dans ces modèles traditionnels, une fois le réseau entraîné, la structure des neurones est définitivement fixée, que ce soit par leurs connexions, par leur pondération ou par le trajet de l'information à travers le réseau. Cela signifie que le réseau réagira toujours de la même manière aux mêmes types d’entrées, sans possibilité d’adaptation après l'entraînement initial.
À l'inverse, les réseaux de neurones liquides (RNL) se distinguent par leur flexibilité. Les neurones eux-mêmes ne sont pas liquides, mais la manière dont ils interagissent évolue en temps réel, conférant à l'adaptation de la structure de circulation de l'information une partie de la capacité de traitement. Cela rend possible la création de modèles plus rapides, nécessitant moins de mémoire, tout en simplifiant la compréhension des décisions qu’ils prennent. Vous la voyez venir, l’IA frugale ET responsable ? 🙂
D’où viennent ces réseaux ?
Ce sont les chercheurs du CSAIL (Computer Science and Artificial Intelligence Laboratory) du MIT, notamment Ramin Hasani et Daniela Rus, qui, en 2020, ont publié le premier article sur les RNL. Leur idée derrière cette technologie était de surmonter certaines limitations des réseaux de neurones traditionnels, principalement leur consommation en ressources (GPU, mémoire) et la difficulté d'expliquer leurs réponses. L'objectif était de créer des modèles légers et autonomes pouvant fonctionner efficacement sur des dispositifs embarqués, comme des robots ou des voitures autonomes, sans dépendre d’une connexion Internet et des ressources du cloud. En plus de ces contraintes, ils souhaitaient que ces modèles permettent une meilleure explicabilité des décisions de l'IA, ce qui est crucial pour des usages comme la robotique ou les véhicules autonomes.
Le point de départ de leur recherche a été l'observation de petits organismes, les nématodes Caenorhabditis elegans, qui utilisent un réseau de seulement 302 neurones. C'est peu, et pourtant cela leur permet d'accomplir des tâches complexes telles que la recherche de nourriture, le sommeil et l’apprentissage de leur environnement. Une telle simplicité démontre qu’un réseau de neurones minimal peut être extrêmement efficace. Leur secret ? Leur structure n'est pas rigide, elle change en fonction des stimuli.
Rassurez-vous, les neurones des nématodes, comme ceux du cerveau humain, n'ont pas de superpouvoir leur permettant de créer des connexions physiques (axones) en temps réel. En réalité, ce n'est pas la structure physique, qui est liée à la génétique et à l'apprentissage, qui change, mais la capacité des nématodes à moduler l'activité synaptique. Les nématodes peuvent ainsi ajuster l’efficacité des synapses et la façon dont les signaux sont transmis à travers le réseau, en fonction de leur environnement et de leurs expériences passées, un phénomène appelé plasticité synaptique. Par exemple, les variations dans la libération de neurotransmetteurs ou la sensibilité des récepteurs permettent au réseau de neurones de réagir différemment, sans que les connexions structurelles changent.
Les chercheurs ont donc modélisé cette plasticité en créant des réseaux "liquides" qui conservent ainsi la capacité de modifier leur structure en fonction des stimuli qu’ils reçoivent, même après leur entraînement. À titre d'exemple, ils ont pu, grâce à cela, créer un premier réseau de seulement 19 neurones capable de maintenir une voiture dans sa voie, là où un réseau traditionnel aurait besoin de plus de 100 000 neurones pour accomplir la même tâche.
Des RNL à Liquid AI et aux LFM
Saisissant bien le potentiel commercial de leur découverte, en 2023, les quatre chercheurs à l'origine des RNL ont fondé Liquid AI, une société spécialisée dans le développement de modèles basés sur cette technologie. Ils ont levé 37,6 millions de dollars de fonds d'amorçage pour financer leurs recherches et cibler des domaines d'application tels que la robotique, les drones et les dispositifs embarqués. Les premiers clients potentiels incluent des entreprises des secteurs automobile et des applications mobiles.
Un an plus tard, il y a quelques jours donc, ils ont annoncé la sortie de trois modèles de langage, appelés LFM (Liquid Foundational Models), exploitant la flexibilité des RNL pour fonctionner dans des environnements à ressources limitées. Le modèle LFM-1B, qui possède 1,3 milliard de paramètres, a été conçu pour opérer avec une faible consommation de ressources. Les versions plus puissantes, telles que LFM-3B et LFM-40B, s’adaptent à des environnements plus complexes, qu’il s’agisse d’applications sur des appareils mobiles, de robots, de drones ou de serveurs cloud.
Concernant le modèle 40B, il s'agit en réalité d'un MoE (Mix of Experts), c'est-à-dire plusieurs modèles spécialisés chacun dans un domaine et qui fonctionnent ensemble. L'avantage de cette architecture, également utilisée sur GPT-4, est qu'à un moment donné, en fonction de la question posée, seul un expert est utilisé, et donc une partie des 40 milliards de poids du modèle est utilisée. Dans le cas du LFM 40B, les experts pèsent 12 milliards.
Alors, ça donne quoi ?
Côté mémoire, il semble que le pari soit gagné. Les LFM peuvent traiter jusqu'à un million de tokens sans que leur utilisation de mémoire n'augmente de manière significative. C’est un atout énorme, surtout quand on sait que les modèles de langage « traditionnels » basés sur des transformateurs consomment des ressources de façon exponentielle lorsque le contexte s’allonge. Cela rend les LFM particulièrement adaptés à des usages variés comme les chatbots, l’analyse de documents ou d’autres scénarios impliquant le traitement de grandes quantités de données séquentielles.
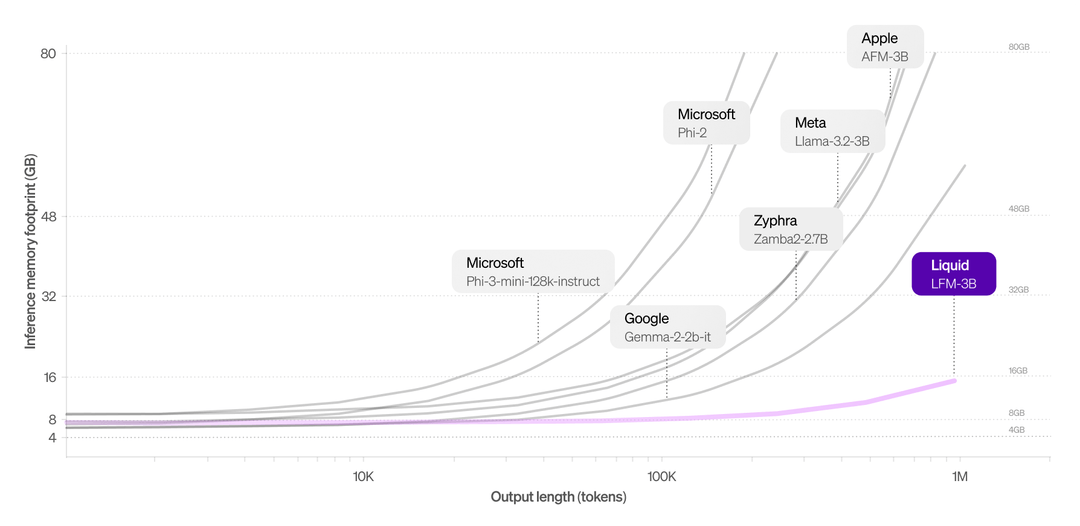
Pour ce qui est de la vitesse, les résultats sont impressionnants. Lorsque j'ai comparé, sur un prompt simple, Liquid LFM-40B à Llama 3.1 70B sur le playground de Perplexity, le temps de production du premier token est certes plus élevé (0,34 s pour Llama contre 0,94 s pour LFM), mais une fois ce token produit, le Liquid LFM-40B est plus de 11 fois plus rapide que le Llama 3.1 70B !
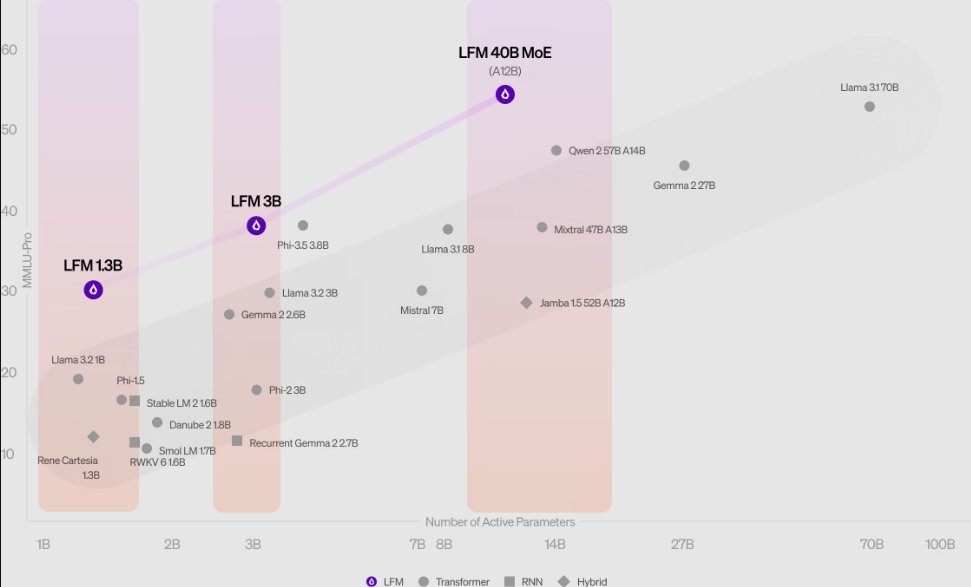
Reste la question de la pertinence du modèle. Et là, il faut évidemment prendre toutes les précautions nécessaires, car rien ne prouve que Liquid AI n'a pas surentraîné son modèle sur les benchmarks. Mais sur le MMLU et l'ARC-C, les résultats obtenus semblent confirmer les performances de ces modèles. Le LFM-1B a même établi un nouveau standard pour les modèles de 1 milliard de paramètres en atteignant une précision supérieure de 5 % par rapport aux réseaux traditionnels de taille équivalente. Le modèle LFM-3B, quant à lui, s’est montré aussi performant que le Phi-3.5 de Microsoft ou les modèles Llama de Meta, tout en consommant nettement moins de ressources.
J'attends cependant des résultats en match réel sur le Chatbot Arena LLM Leaderboard pour avoir une vue plus pragmatique des performances de ce modèle par rapport au reste du marché.
En conclusion
Les performances des RNL, combinées à leur faible empreinte mémoire, en font une solution prometteuse pour de nombreuses applications, depuis la gestion des interactions en temps réel jusqu’à l’analyse documentaire intensive.
Les réseaux de neurones liquides représentent une avancée vers des modèles plus adaptatifs, moins gourmands en ressources et en énergie. Leur capacité à apprendre en continu, en s'inspirant des systèmes biologiques, pourrait transformer le paysage de l’intelligence artificielle de demain.